Calling CUDA device function from OpenACC Fortran kernel
OpenACC is known to be a fast method of developing quite efficient GPU-enabled applications. It is also possible to mix CUDA kernels and libraries with OpenACC ke...
OpenACC is known to be a fast method of developing quite efficient GPU-enabled applications. It is also possible to mix CUDA kernels and libraries with OpenACC ke...
Applied Parallel Computing LLC has given a talk at the International Summer Supercomputing Academy, Lomonosov Moscow State University, Moscow.
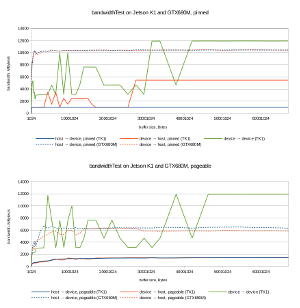
Chart on the left shows the bandwidths of memory transfers on Jetson K1 (Click to enlarge). For the baseline we also added GTX680M’s host-device and device-host (...
We finally got the most wanted Jetson K1 board in the house! In this post we show how to turn a just unboxed tiny board into fully-functional CUDA development nod...
Applied Parallel Computing LLC has delivered a GPU computing training at the “High Performance Computing on GPUs” conference, Perm State University, Russia
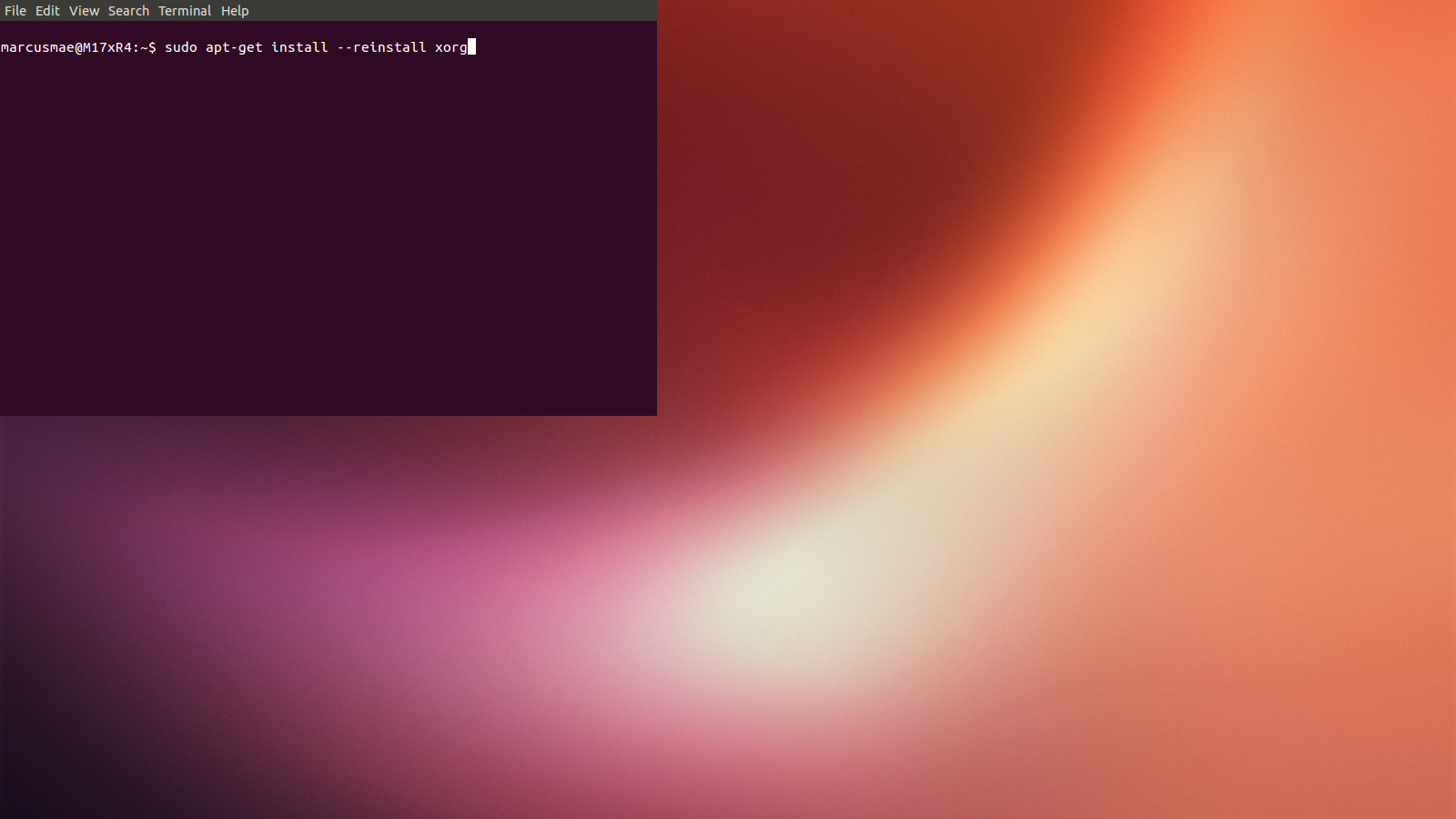
After installing CUDA driver from NVIDIA website, Ubuntu 13.04/14.04 window manager decorations (Unity, via Compiz) may stop working properly on Optimus machines ...
Applied Parallel Computing LLC will participate in CSCS-USI Summer School, to be held from 30 June to 10 July at Hotel Serpiano (Ticino, Switzerland). We will giv...
Consider we need to profile the following MPI-CUDA program on GPU cluster. The most obvious way to profile this code on console-only cluster would be to invoke th...
If cuda-gdb throws Program received signal CUDA_EXCEPTION_4, Warp Illegal Instruction. for the following code line:
Together with out colleagues from CSCS we presented introductory talks on GPU and CUDA on the first day of HPC Advisory Council Switzerland.